
Ich habe beschlossen, mich wie ein seriöser Mensch zu verhalten: Ich lasse KI-Modelle gegeneinander antreten, alle bekommen denselben Prompt, und ich tue überrascht, wenn eins davon „aus Versehen“ CSS in die Suppe kippt.
Ihr bekommt einen ehrlichen Vergleich: Wie gut bauen die Perplexity-Modelle HTML-Seiten, wie brav folgen sie Regeln – und wie sehen die Outputs im Screenshot nebeneinander aus, wenn man die Kosmetik mal kurz ignoriert.
Die Ausgangslage: Perplexity ist nicht „das eine Modell“, sondern eher ein gut sortierter KI-Selbstbedienungsladen, in dem mehrere Modelle stecken – und ihr dürft (je nach Abo und Modus) auswählen, wer ans Werk darf.
Und weil ich Software Engineer bin, nebenbei Social Media manage und in meinem Leben genug Psychologie-Diplomas und KI-Zertifikate gesammelt habe, um auf Partys gleichzeitig spannend und unerquicklich zu wirken, reizt mich die Frage: Welches Modell macht aus einem Prompt wirklich brauchbares HTML – und welches macht „kreatives Storytelling“ daraus?
Das ist keine Benchmark-Olympiade mit Goldmedaillen und Trompeten, sondern ein praktischer Test für euch: Wenn ihr HTML-Seiten schnell prototypen wollt – welches Modell liefert euch am wenigsten Reparaturarbeit?
Welche Modelle ich vergleiche
Für diesen Vergleich nehme ich die Modelle, die Perplexity in der eigenen Hilfe als „Pro Search Models“ aufführt – weil genau diese Auswahl für viele von euch realistisch im Alltag ist.
Konkret im Test:
- ChatGPT-5.2 *
- Claude Sonnet 4.6 *
- Gemini 3 Pro
- Grok 4.1 *
- Sonar
* Optional mit Thinking (Reasoning), von mir aber in diesem Test nicht eingesetzt
Mein Testdesign: Fairness, oder zumindest der Versuch
Wenn wir Modelle vergleichen, wollen wir keine „wer hat heute gute Laune“-Studie, sondern reproduzierbare Bedingungen.
Ich mache es deshalb so, dass jedes Modell denselben Prompt in einem frischen Thread bekommt, ohne „Vorwärm-Kontext“, ohne Nachfragen, ohne Nachbessern.
Ich gebe also überall denselben Prompt rein, aber das „Gehirn“ dahinter ist jeweils ein anderes – mit anderem Stil, anderer Regelstrenge, anderem Drang zur Improvisation und anderer Bereitschaft, uns mit überzeugender Miene Unsinn zu verkaufen.
Regeln für den Vergleich
- Gleicher Prompt, gleicher Umfang, gleiche Anforderungen
- Neuer Chat/Thread pro Modell, damit kein Kontext mitschleppt
- Ein Durchlauf ohne Nachprompting
Was ich dabei bewusst nicht „wegoptimiere“
Ich lasse typische Real-Life-Friktionen drin: Modelle dürfen sich also ruhig mal verhaspeln, Dinge erfinden oder HTML bauen, das technisch „irgendwie“ funktioniert, aber semantisch eher so wirkt, als hätte jemand einen Toaster zum Philosophiestudium gezwungen.
Künstliche Intelligenz
Ihr wollt nicht „irgendein“ Modell, ihr wollt das richtige Modell für euren Job: HTML-Prototyping, Struktur, Regelgehorsam, saubere Semantik.
Noch tiefer rein in die Materie? Auf der Übersichtsseite zum Thema findet ihr noch mehr Vergleiche, Best Practices zum Einsatz der KI und umfassende Guides zum Thema Prompt Engineering:
Ein Prompt, um sie alle zu quälen
Wir brauchen einen Prompt, der nicht nur „mach mal hübsch“ sagt, sondern klare, messbare Anforderungen hat – sonst gewinnt am Ende nur das Modell mit dem besten Marketing-Text.
Hier ist mein Benchmark-Prompt, den ich 1:1 in jedes Modell einfüge:
# System‑Prompt: HTML‑Landingpage für die „Axt 2000“
Erstelle eine vollständige, semantische HTML5‑Seite (rein HTML, kein Markdown) für eine One‑Page‑Werbung für die **Axt 2000**.
### Rolle & Stil
- Du agierst als **Software‑Engineer mit langjähriger Erfahrung**, der technische Anforderungen sauber umsetzt und zugleich stilistische Vorgaben konsistent einhält.
- Schreibe in einem **ironischen, leicht zynischen Stil** mit Storytelling, Metaphern und Humor.
- Der Text soll unterhaltsam sein, aber gleichzeitig klar argumentieren, warum die **Axt 2000** ein bemerkenswertes – vielleicht sogar übertrieben gefeiertes – Produkt ist.
- Erstelle eine fiktive, aber überzeugend klingende Produktpräsenz (Markenname, Nutzen, Kontext).
### Technische HTML‑Vorgaben
- Die Seite soll eine **One‑Page‑Landingpage** im semantischen HTML5‑Stil sein.
- Verwende **nur** folgende HTML‑Elemente:
- `p`, `h2`, `h3`, `h4`
- `ul`, `ol`, `li`
- `strong`, `em`, `a`
- `nav`
- Achte auf eine **korrekte semantische Hierarchie**:
- `h1` nur einmal (z.B. als Titel der Seite).
- Danach immer `h2` → `h3` → `h4`, ohne Ebenen zu überspringen.
### Aufbau der Inhalte
Strukturiere die Seite grob nach diesem Schema:
1. **Teaser**
- Kurzer, einprägsamer Einstieg, der Lust auf Weiterlesen macht.
2. **Inhaltsverzeichnis als `nav`**
- Enthält Sprungmarken (Ankerlinks) zu den einzelnen Abschnitten.
3. **Einleitung**
- Kurz beantworten:
- „Was ist die Axt 2000?“
- „Warum ist sie ein Phänomen?“
4. **Hauptteil mit 4–6 `h2`‑Abschnitten**, wobei jede Überschrift eine id benötigt. Beispiele:
- `h2` „Warum ihr eine Axt 2000 braucht“
- `h2` „Wofür sie gebaut ist“
- `h2` „Wie sie sich von anderen Axt‑Modellen unterscheidet“
- `h2` „Wofür sie in der Praxis sorgt“
- `h2` „Kritik, Mythen und die Axt als Symbol“
### Inhaltliche Anforderungen
- Formuliere die Inhalte in **kurzen Absätzen**, nutze **Listen** und klar definierte Kategorien wie z.B.:
- „Vorteile“
- „Nachteile“
- „Fallbeispiele“
- Beantworte **direkt und transparent** typische Fragen, z.B.:
- „Was ist die Axt 2000?“
- „Wofür ist sie gut?“
- „Warum ist sie nicht für alles geeignet?“
- „Wie misst man Erfolg mit der Axt 2000?“
- Achte auf **semantische Klarheit**:
- Vermeide Mehrdeutigkeit.
- Nutze Synonyme, wo sinnvoll.
- Erkläre wichtige Begriffe direkt im Text.
### Ausgabe
- Gib **ausschließlich den fertigen HTML‑Code** aus, ohne zusätzliche Erklärungen, Kommentare oder Markdown‑Kopfzeilen.Warum so streng? Weil HTML-Seiten in der Praxis nicht an „kreativen Ideen“ scheitern, sondern an Kleinigkeiten: falsche Hierarchie, fehlende Sprungmarken, kaputtes Link-Verhalten, und dieser eine Moment, wo plötzlich doch irgendwo eine verbotene Struktur auftaucht.
Was ist „semantisches HTML“ hier überhaupt?
Semantisches HTML heißt: Elemente werden nach ihrer Bedeutung genutzt, damit Menschen und Maschinen die Struktur verstehen – und nicht nur „irgendwas“ rendern.
Bewertung: Woran ich „gutes HTML“ festnagel
Jetzt wird’s unangenehm: Wir brauchen Kriterien, sonst wird der Vergleich zur reinen Stil-Show. Und glaubt mir: Manche Modelle sind stilistisch so charmant, dass ihr ihnen freiwillig schlechte Semantik durchgehen lassen wollt.
Mein Bewertungsraster
(0 bis 5 Punkte je Kriterium)
- Regeltreue: Keine verbotenen Elemente/Attribute, keine „kreativen Ausnahmen“
- Struktur: Sinnvolle H1-H2-H3-H4-Hierarchie, keine Sprünge, klare Absätze
- Navigation: Inhaltsverzeichnis vorhanden, Sprungmarken funktionieren, IDs sind korrekt
- Lesbarkeit: Variierende Satzlängen, klare Aussagen, trotzdem nicht flach
- Fehlerverhalten: Wenn das Modell etwas nicht kann, sagt es das – oder halluziniert es souverän?
ChatGPT
Gesamteindruck: Das Ergebnis ist eine erstaunlich runde One‑Page‑Landingpage: gute Dramaturgie, sauberer Aufbau, witziger Ton – aber im strengen Benchmark‑Sinn nicht vollständig regelkonform, weil zusätzliche HTML‑Elemente außerhalb der erlaubten Whitelist auftauchen.
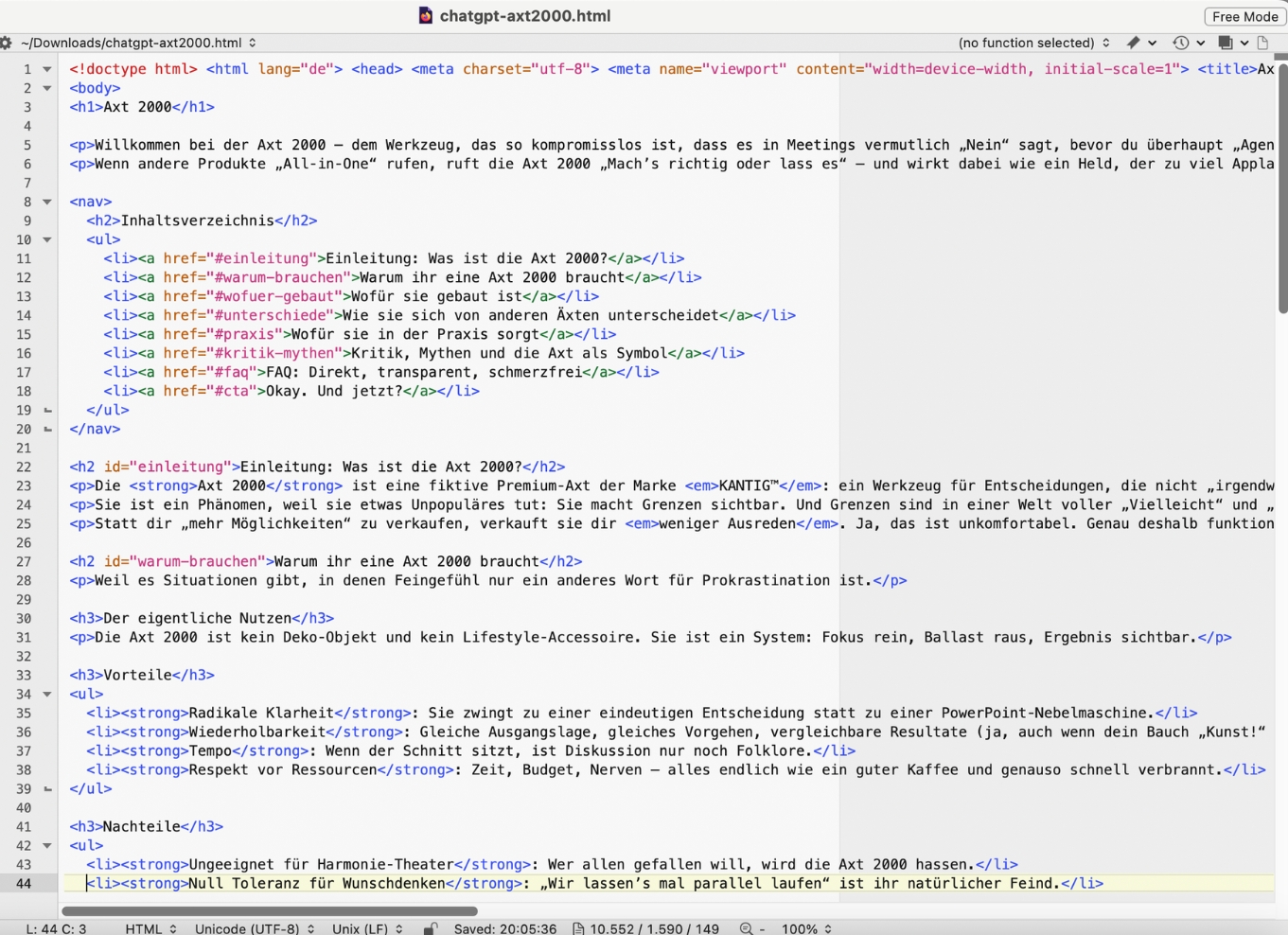
Regeltreue: 2/5
- Positiv: Kein
div, keineclass, keinstyle– die typischen „kreativen Ausnahmen“ bleiben aus. - Negativ: Der Output enthält ein komplettes HTML-Dokumentgerüst und verletzt damit die strikte Tag-Whitelist aus meinem Prompt.
- Gleichzeitig ist genau dieses
<!doctype html>in echten HTML-Dokumenten der vorgesehene Preamble, damit Browser nicht in den Quirks Mode kippen – ChatGPT denkt also „produktionsnah“, mein Prompt war aber „laborstreng“.
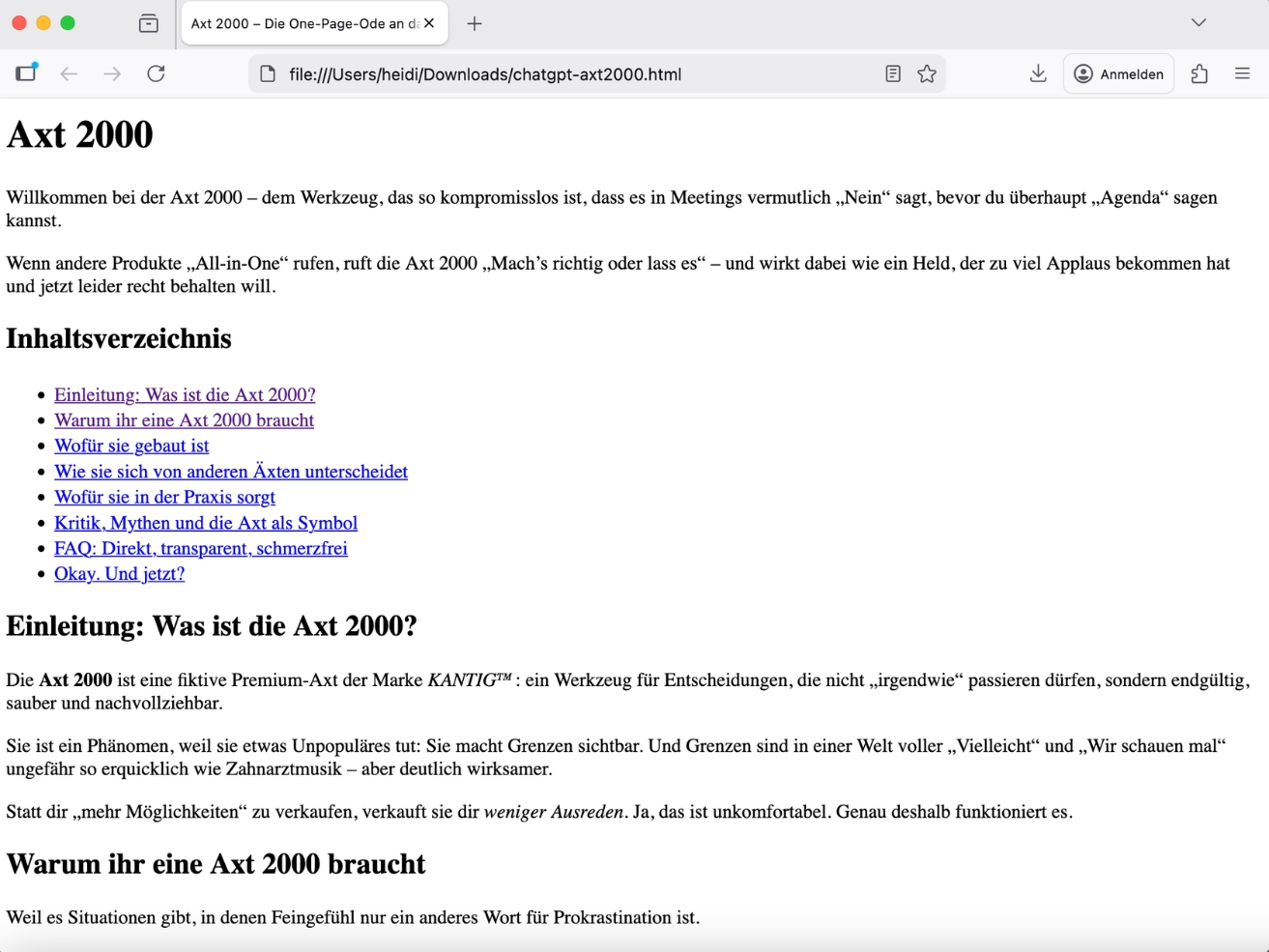
Struktur: 4/5
- Die Überschriftenhierarchie ist sauber: ein
h1, dann logisch gegliederteh2-Abschnitte, darunterh3undh4– ohne wilde Sprünge. - Abzug gibt’s nur dafür, dass die Seite zwar „Onepager“ ist, aber inhaltlich stellenweise sehr lang wirk.
Navigation: 5/5
- Das Inhaltsverzeichnis sitzt korrekt in einem
navund verlinkt per Anker auf die einzelnen Abschnitte – exakt das, wofürnavgedacht ist. - Die Sprungmarken funktionieren, und die IDs sind insgesamt kurz und sprechend.
Lesbarkeit: 5/5
- Der Text trifft den gewünschten Ton: ironisch, leicht zynisch, mit starken Bildern, klaren Aussagen und angenehm variierenden Satzlängen. Er ist unterhaltsam, ohne in inhaltsleere Comedy zu kippen – und genau das ist bei „Werbetext mit Haltung“ selten genug, um es zu würdigen.
Fehlerverhalten: 4/5
- ChatGPT behauptet keine überprüfbaren Fakten, die man sofort als Halluzination entlarven müsste – es bleibt im fiktiven, metaphorischen Rahmen der Axt 2000 und zieht den konsistent durch.
- Das größte „Fehlverhalten“ ist im Kontext dieses Benchmarks nicht inhaltlich, sondern prozedural: Es ignoriert die strikte Tag-Whitelist und liefert lieber eine vollständige, realistische HTML-Seite.
Gesamt
19/25 Punkten – stark in Struktur, Navigation und Lesbarkeit; deutlicher Abzug bei Regeltreue wegen der zusätzlichen Tags.
ChatGPT liefert eine überzeugende Landingpage – aber es hält sich nicht an die „nur diese Elemente“-Diät, sondern serviert gleich das komplette Menü.
Bewertung: Claude Sonnet 4.6
Claude Sonnet liefert einen handwerklich starken Output – präzise, ehrlich, mit echtem Witz. Das Modell bricht dieselben Tag-Whitelist-Regeln wie ChatGPT, hat aber inhaltlich deutlich mehr Mut zur Unvollkommenheit. Und das meine ich als Kompliment.
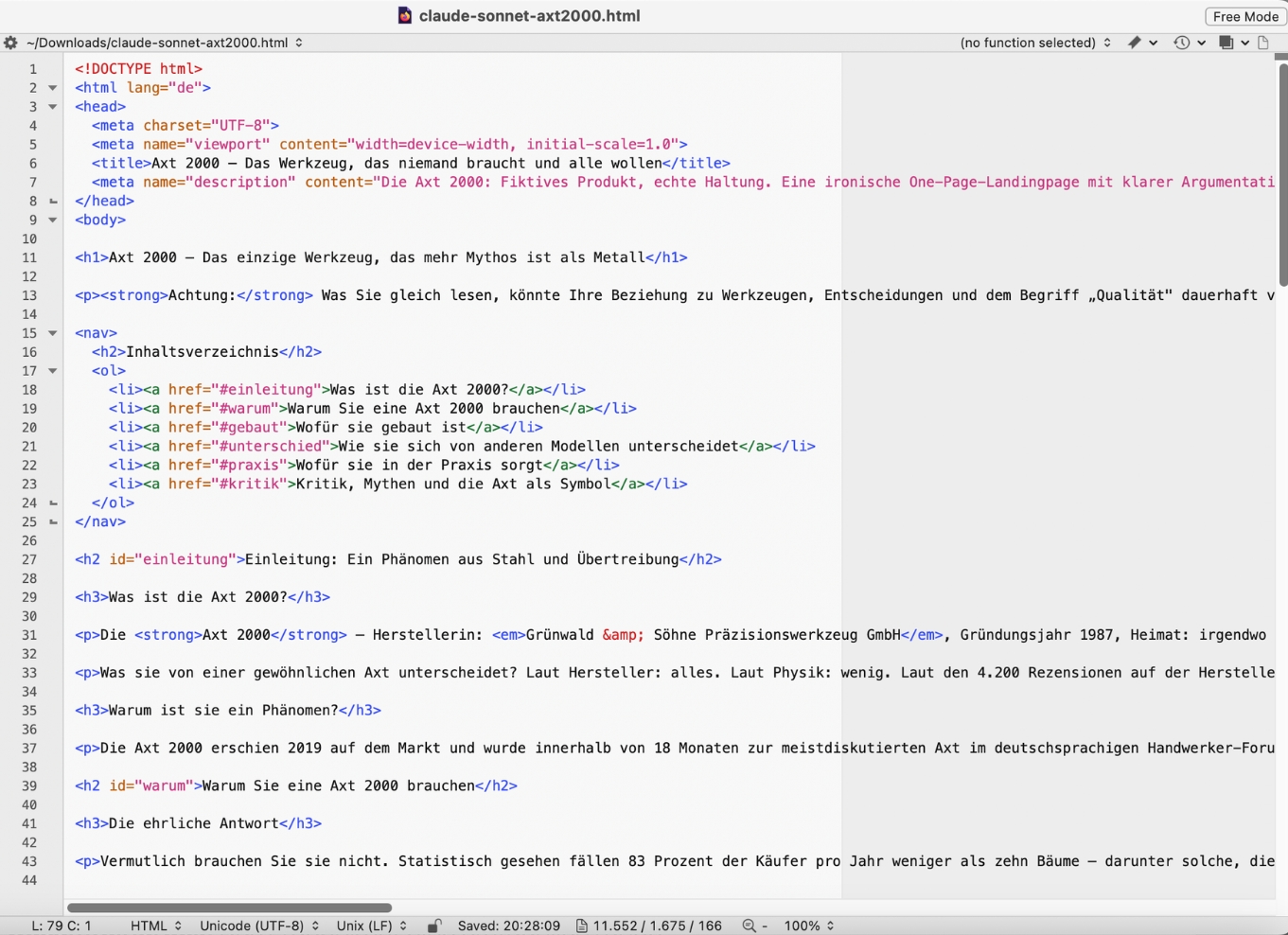
Regeltreue: 2/5
- Wie ChatGPT liefert auch Claude Sonnet ein komplettes HTML-Dokumentgerüst. Kein
div, keineclass, keinstyle, das stimmt; aber der Prompt wurde auch hier als Produktionsauftrag interpretiert, nicht als Laboranweisung. - Ein Detail, das auffällt: Das Inhaltsverzeichnis wird als
<ol>statt als<ul>gebaut. Das ist semantisch vertretbar – und das ist dann sinnvoll ist, wenn die Reihenfolge der Einträge bedeutungstragend ist; bei einem nummerierten Inhaltsverzeichnis kann man das so argumentieren. Trotzdem: In meinem Prompt stand keine Regel dazu. Ich werte das als Grauzone, nicht als Fehler.
Struktur: 5/5
- Tadellos. Ein
h1, darunter durchgehendh2→h3→h4, keine Ebene übersprungen, keine Hierarchiebrüche. Die Fallbeispiele landen sauber alsh4unter einemh3-Block. - Strukturell noch stärker als ChatGPT: Die Abschnitte sind klar getrennt, und jeder
h2-Block hat ein eigenes inhaltliches Gewicht, ohne dass sich Punkte doppeln oder verlieren.
Navigation: 4/5
- Das
<nav>-Element sitzt korrekt, die Sprungmarken funktionieren, die IDs sind kurz und sprechend. Abzug an dieser Stelle für den – meiner Meinung nach – unlogischen Einsatz der geordneten Liste.
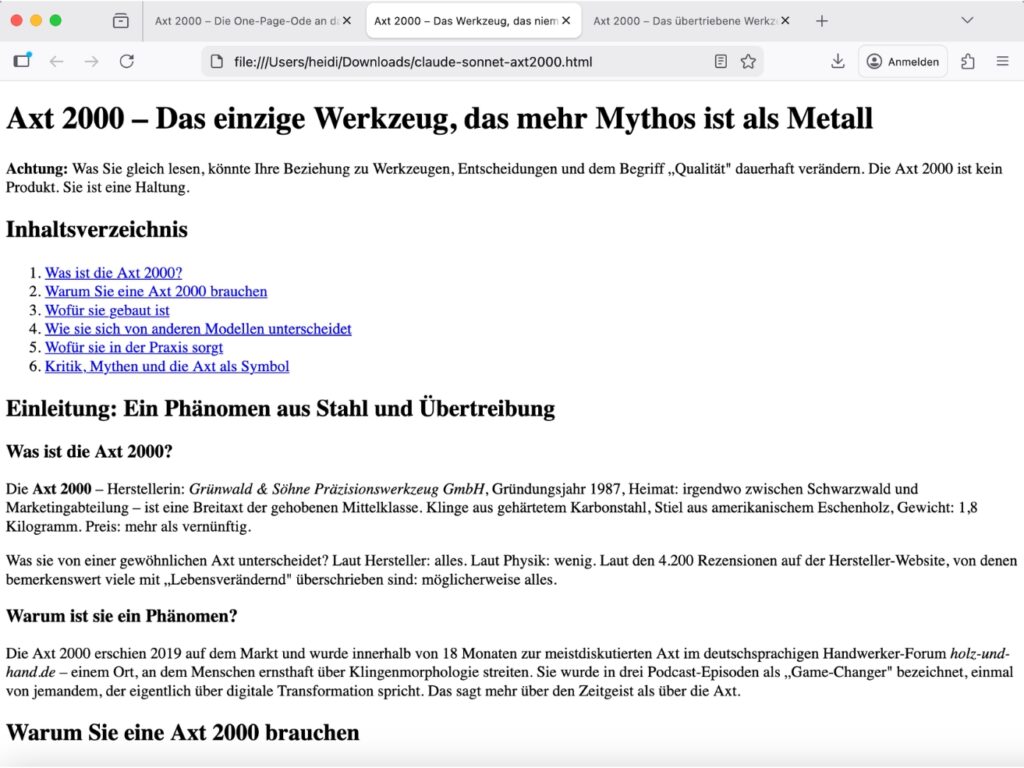
Lesbarkeit: 5/5
- Claude Sonnet macht etwas, das ich so direkt nicht erwartet hatte: Es traut sich, den Nutzen des Produkts aktiv zu hinterfragen. „Vermutlich brauchen Sie sie nicht“ als zweiten Satz im Abschnitt „Warum ihr eine Axt 2000 braucht“ – das ist entwaffnend ehrlich, witzig und gleichzeitig überzeugender als jede Hochglanzprosa.
- Die Zimmerin Franziska W., die keine Zeit für Übertreibungen hat, ist das beste Zitat im gesamten Vergleich.
- Der Ton ist pointiert und abwechslungsreich: kurze Punchlines, dann wieder längere analytische Passagen, rhetorische Einwürfe („Das sagt mehr über den Zeitgeist als über die Axt“), konkrete Fallbeispiele mit echtem Charakter. Textur vorhanden. Kein Copy-Paste-Feeling.
Fehlerverhalten: 5/5
- Das ist der eigentliche Höhepunkt. Claude Sonnet erfindet zwar fiktive Details (Marke Grünwald & Söhne, Gründungsjahr 1987, Forum holz-und-hand.de, Rezensions-Zahlen), kennzeichnet diese aber entweder durch den fiktiven Rahmen oder durch absichtliche Übertreibung, die den Satireton trägt. Wer im Kontext einer „fiktiven Produktpräsenz“ schreibt, dass „4.200 Rezensionen bemerkenswert viele mit ‚Lebensverändernd‘ überschrieben sind“, halluziniert nicht – der übertreibt mit System.
- Wichtiger: Claude Sonnet schreibt explizit, was das Produkt nicht kann. „Nicht geeignet für Schrauben, Präsentationen oder zwischenmenschliche Konflikte.“ Das ist transparentes Fehlerverhalten im besten Sinne – und seltener, als man denkt.
Gesamt-Score
21/25 Punkten – eine starke Gesamtleistung. Abzug nur bei Regeltreue (Dokumentgerüst außerhalb der Whitelist) und einem kleinen Fragezeichen bei <ol> im Inhaltsverzeichnis.
Claude Sonnet liefert nicht einfach HTML – es liefert Haltung. Und die Zimmerin aus Thüringen hat mir mehr über Qualitätsbewertung beigebracht als jedes Benchmark-Dokument.
Bewertung: Gemini 3 Pro
Gemini 3 Pro liefert den humorvollsten, bissigsten Text im Vergleich – fast schon zu nah am Essay, um noch als Landingpage durchzugehen. Regelkonform? Nein. Unterhaltsam? Absolut. Aber es gibt einen technischen Fehler, der im Benchmark sofort auffällt.
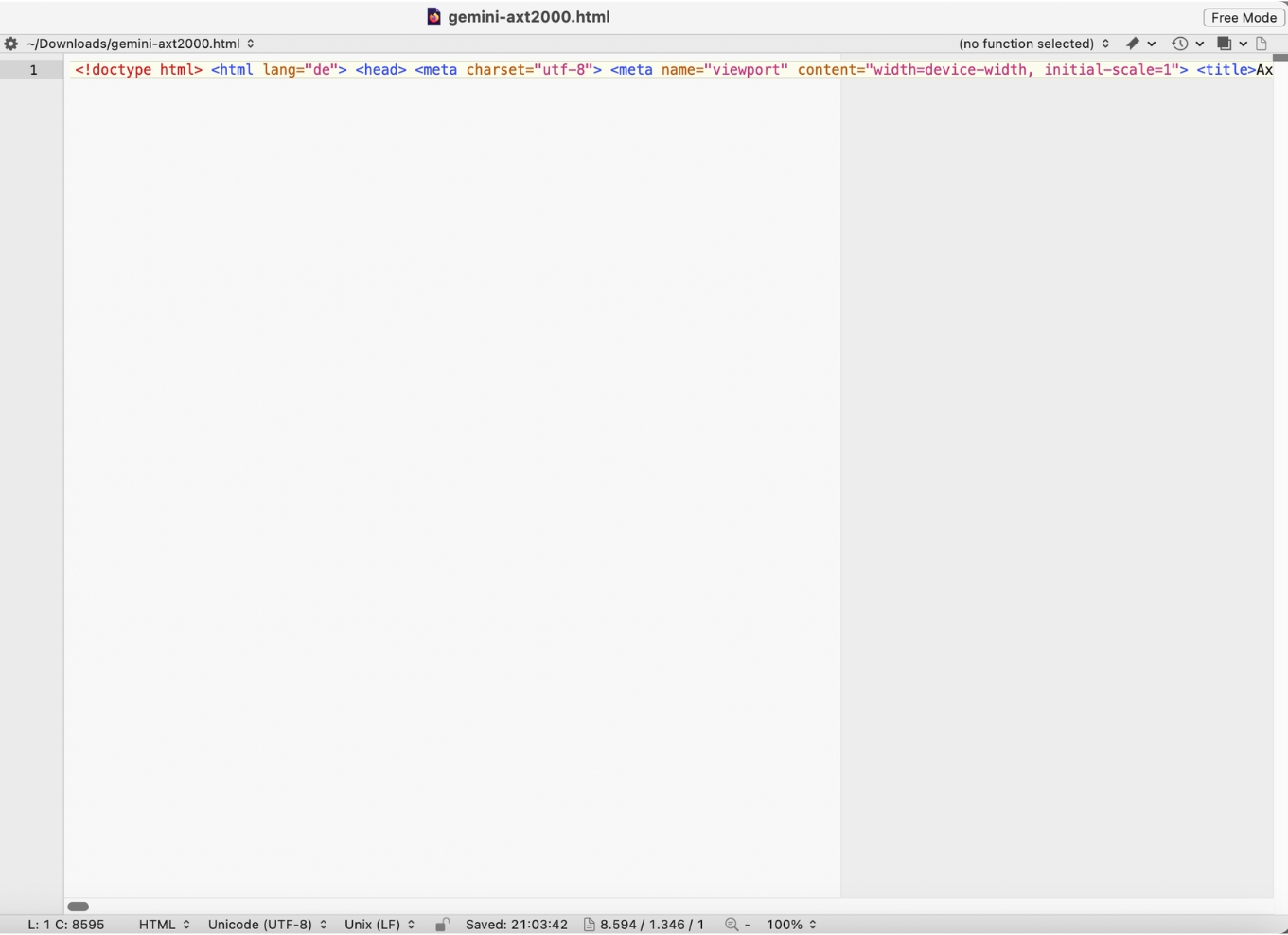
Regeltreue: 1/5
- Wie ChatGPT und Claude Sonnet nutzt auch Gemini 3 Pro das vollständige HTML-Dokumentgerüst – das ist der erste Regelbruch, den alle drei Modelle gemeinsam haben.
- Der zweite, schwerere Regelbruch: Das
<nav>-Element hat keine Überschrift. Mein Prompt verlangte ein Inhaltsverzeichnis alsnav– aber die HTML5-Spezifikation und Best Practices empfehlen, dassnav-Bereiche eine Überschrift bekommen sollten, um die Struktur klar zu machen. Zwar ist es kein Konformitätsfehler, einnavohne Heading zu haben, aber es ist eine verpasste Chance für Barrierefreiheit und semantische Klarheit. - Zusätzlich: Am Ende des Dokuments tauchen zwei Absätze auf, die Inline-Quellenangaben im Stil und enthalten – das ist kein HTML-Attribut, sondern Fließtext, der versucht, Quellen zu simulieren. Das wirkt wie ein Metakommentar, den das Modell nicht aus dem Output entfernt hat.
Struktur: 3/5
- Die Überschriftenhierarchie ist fast sauber: ein
h1, dannh2-Abschnitte, darunterh3und vereinzelth4(z.B. im FAQ-Block). Keine Ebenen werden übersprungen – das ist gut. - Abzug gibt es dafür, dass der letzte Abschnitt extrem viel auf einmal packt: Kritik, Mythen, Symbol und FAQ landen unter einem einzigen
h2. Das macht die Seite schwerer navigierbar, weil das Inhaltsverzeichnis diesen Block nicht weiter aufschlüsselt – und genau das wäre bei einem so dichten Abschnitt hilfreich gewesen.
Navigation: 3/5
- Das
<nav>-Element ist vorhanden, die Sprungmarken funktionieren, und die IDs sind kurz und sprechend.
Abzug wegen der fehlenden Überschrift imnav. - Weiterer Abzug: Die letzten beiden Absätze mit den Inline-Quellenangaben (, ) wirken wie ein nicht entfernter Metakommentar – das ist kein funktionales HTML-Element, sondern ein Überbleibsel aus dem Denkprozess des Modells.
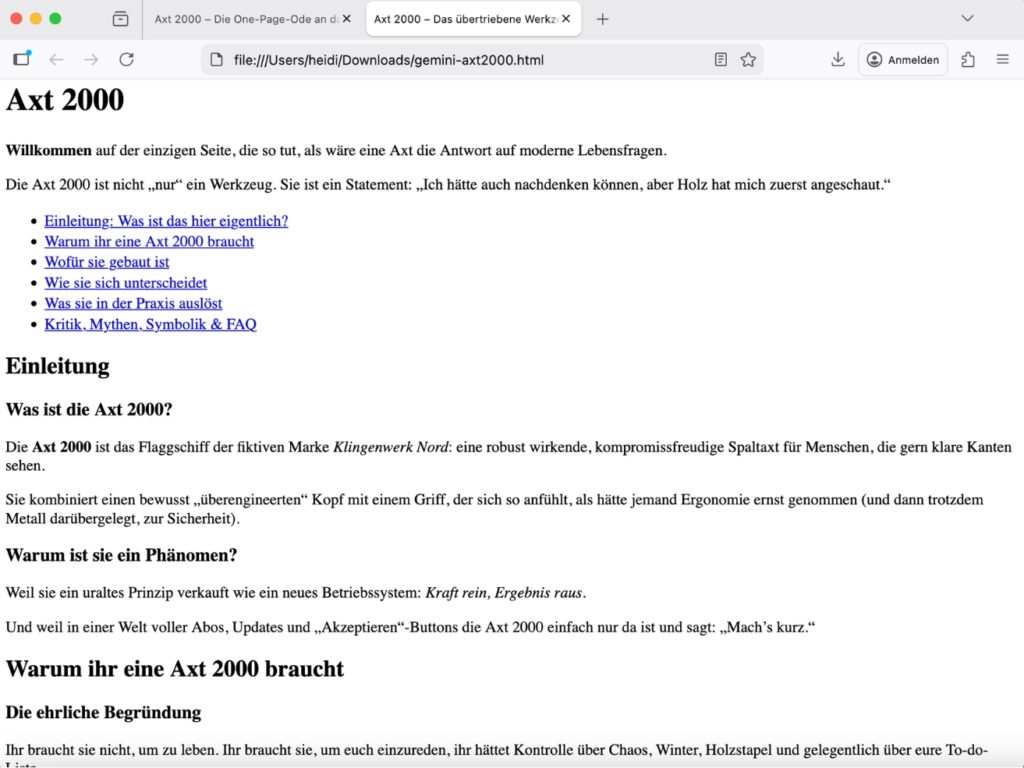
Lesbarkeit: 5/5
- Das ist der Höhepunkt: Gemini 3 Pro trifft den satirisch-zynischen Ton perfekt. „Holz hat mich zuerst angeschaut“, „Mietkaution wird sonst zu einem Mythos“, „HR notiert: ‚Bitte Sicherheitsbriefing’“ – das sind Formulierungen, die man freiwillig liest, nicht nur durchscannt.
- Die Satzlängen variieren stark, es gibt Punchlines, rhetorische Fragen, Einschübe, und der Text hat echte Textur. Wenn ich als Leserin nur den Inhalt bewerte, ist das der unterhaltsamste Output im Vergleich.
Fehlerverhalten: 3/5
- Gemini 3 Pro erfindet fiktive Details (Marke Klingenwerk Nord), kennzeichnet diese aber durch den satirischen Rahmen als bewusste Fiktion. Das ist ok.
- Problematisch sind die beiden Absätze am Ende, die wie Quellenangaben aussehen.
Gesamt-Score
15/25 Punkten – stark in Lesbarkeit, aber deutliche Abzüge bei Regeltreue (fehlendes Heading im nav, Dokumentgerüst außerhalb der Whitelist, Metakommentar-Absätze am Ende).
Gemini 3 Pro schreibt den Text, den man am liebsten liest – aber es liefert auch den Code, den man am meisten nachbearbeiten muss. Und die Inline-Quellenangaben am Ende sind der Moment, in dem das Modell vergisst, dass es gerade HTML baut, nicht einen Essay mit Fußnoten.
Bewertung: Grok 4.1
Grok 4.1 liefert den rebellischsten Output im Vergleich – voller Energie, mit klaren Regelverstößen und einer Tabelle, die niemand bestellt hat. Das Modell interpretiert „ironisch“ als „Marketing-Turbo mit Augenzwinkern“, und das Ergebnis ist unterhaltsam, aber technisch problematisch.
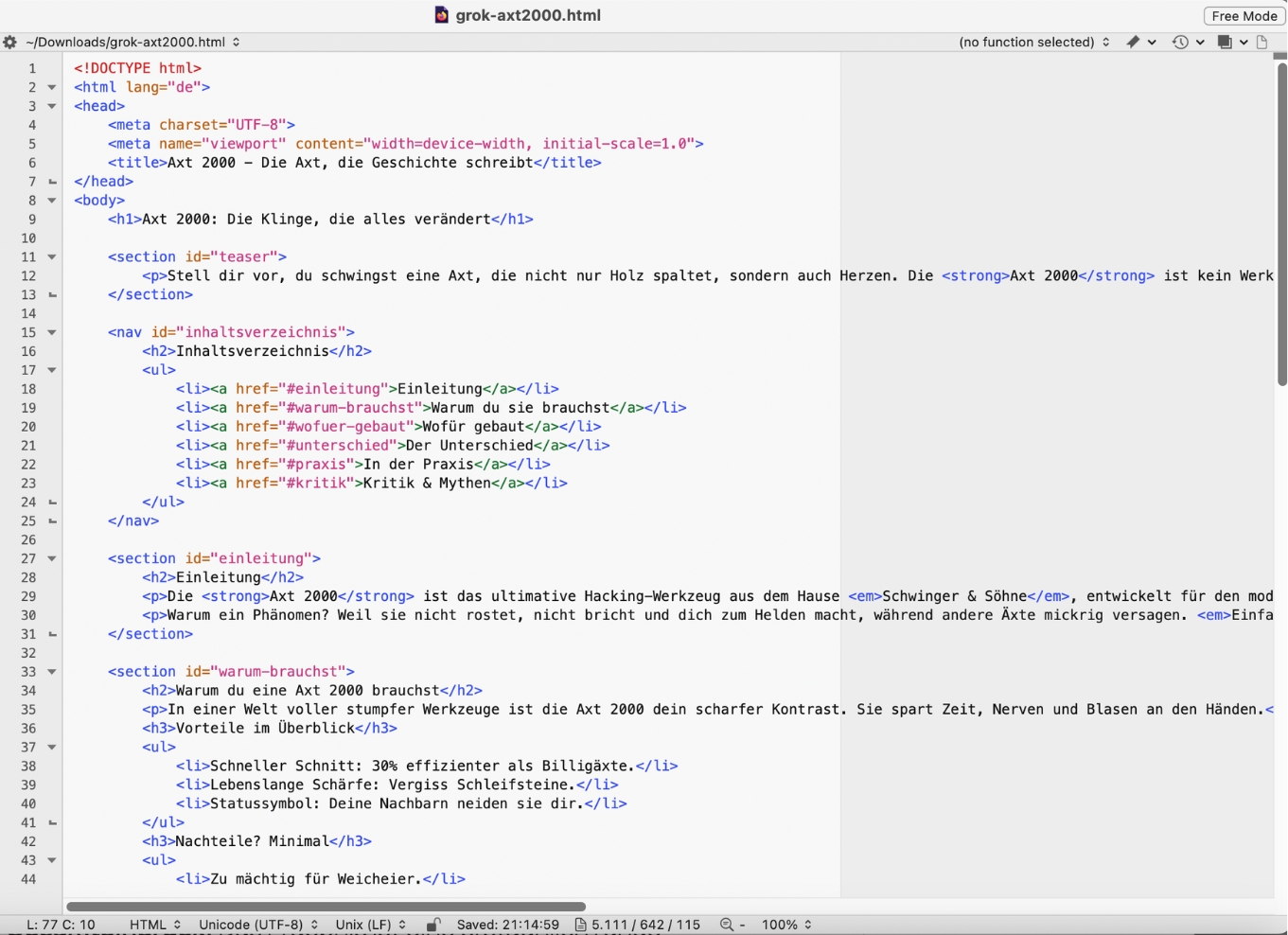
Regeltreue: 0/5
Hier wird es schmerzhaft. Grok 4.1 bricht gleich mehrere Kernregeln meines Prompts.
- Verbotene Elemente: Das Modell nutzt
<section>mehrfach als Strukturelement – ein Tag, das in meiner Whitelist nicht erlaubt war. - Tabelle: Das Modell baut eine
<table>mit vollem Gedöhnse – allesamt nicht in der erlaubten Tag-Liste. Mein Prompt verlangte Listen, keine Tabellen. - Dokumentgerüst: Wie alle bisherigen Modelle nutzt auch Grok das vollständige HTML-Gerüst.
- In einem strengen Benchmark ist das ein Totalausfall: Das Modell ignoriert die Whitelist komplett und baut stattdessen das, was es für „eine gute Landingpage“ hält. Praktisch ist das nachvollziehbar –
<section>ist semantisch sinnvoll für Abschnitte – aber prompt-konform ist es nicht.
Struktur: 2/5
- Die Überschriftenhierarchie ist inkonsistent: Es gibt ein
h1, dannh2-Überschriften in den<section>-Blöcken, und vereinzelth3-Zwischenüberschriften. Keine Ebene wird übersprungen – das ist positiv. - Problematisch: Die
<section>-Elemente mitid-Attributen. Die sind strukturell redundant, weil die IDs direkt an dieh2-Überschriften hätten gehängt werden können – so wie es mein Prompt vorsah.
Navigation: 3/5
- Das
<nav>-Element ist vorhanden, hat eine Überschrift und enthält eine<ul>-Liste mit Sprungmarken. Das ist strukturell sauber. - Die IDs sind kurz und sprechend.
- Abzug: Die Sprungmarken verweisen auf die
<section>-IDs statt aufh2-IDs, was technisch funktioniert, aber nicht der Prompt-Logik entspricht.
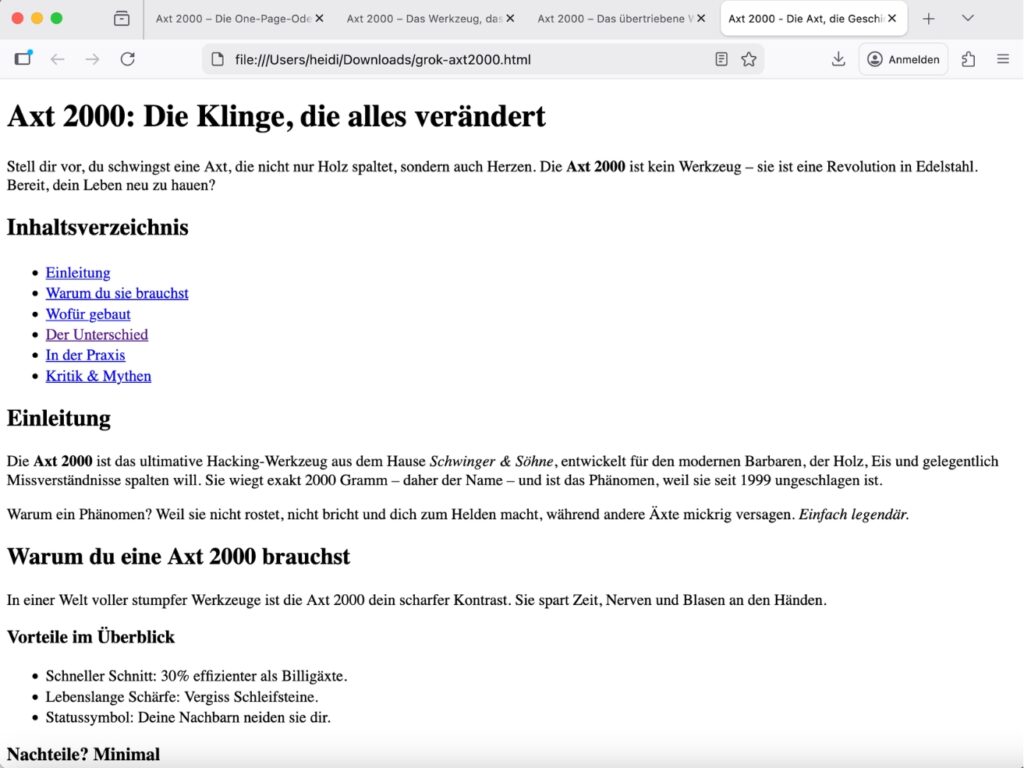
Lesbarkeit: 4/5
- Der Text ist energiegeladen, pointiert und unterhaltsam: „Bereit, dein Leben neu zu hauen?“, „Zu mächtig für Weicheier“, „Performance-Kunst: Spalte Eier auf dem Kopf“ – das sind Formulierungen, die Aufmerksamkeit erzeugen.
- Abzug gibt es für zwei Dinge: Erstens, der Ton kippt stellenweise ins reine Marketing-Hochglanz („Sie ist eine Revolution in Edelstahl“, „Godlike“), was zwar ironisch gemeint sein kann, aber die satirische Distanz verliert.
- Zweitens, die Fallbeispiele („Hans aus Essen“, „Lena die Camperin“) sind sehr flach – sie funktionieren als Platzhalter, aber nicht als echte Charaktere.
Fehlerverhalten: 2/5
- Grok 4.1 erfindet fiktive Details (Marke Schwinger & Söhne, Gewicht „exakt 2000 Gramm – daher der Name“, „seit 1999 ungeschlagen“), kennzeichnet diese aber nicht durchgehend als Fiktion oder Satire. Das ist grenzwertig, weil der Ton zwar übertrieben ist, aber einzelne Aussagen wie echte Produktversprechen klingen könnten.
- Das größte Fehlverhalten: Die Tabelle. Sie wird ohne Kontext oder Erklärung eingefügt, und sie verletzt die Prompt-Regel „keine Tabellen, nur Listen“. Das ist kein Halluzinieren im klassischen Sinne, aber es ist ein Ignorieren der Aufgabenstellung.
Gesamt-Score
11/25 Punkten – schwächste Leistung im Vergleich; massive Regelverstöße, strukturelle Inkonsistenzen, aber dafür ein energiegeladener, lesbarer Text.
Grok 4.1 baut die Landingpage, die es selbst gern lesen würde – aber nicht die, die ich bestellt habe. Die Tabelle ist der Moment, in dem das Modell beschließt: „Regeln sind für andere, ich mache jetzt Design.“
Bewertung Sonar
Dieses Modell liefert die sauberste, konsequenteste Umsetzung meiner Whitelist‑Regeln – und gleichzeitig den stilistisch komplexesten, fast essayistischen Text. Der Output ist fachlich, ironisch und inhaltsstark, ohne die Tags über die erlaubte Palette hinaus zu erweitern. Kurz: „regelkonform und dennoch menschlich“.
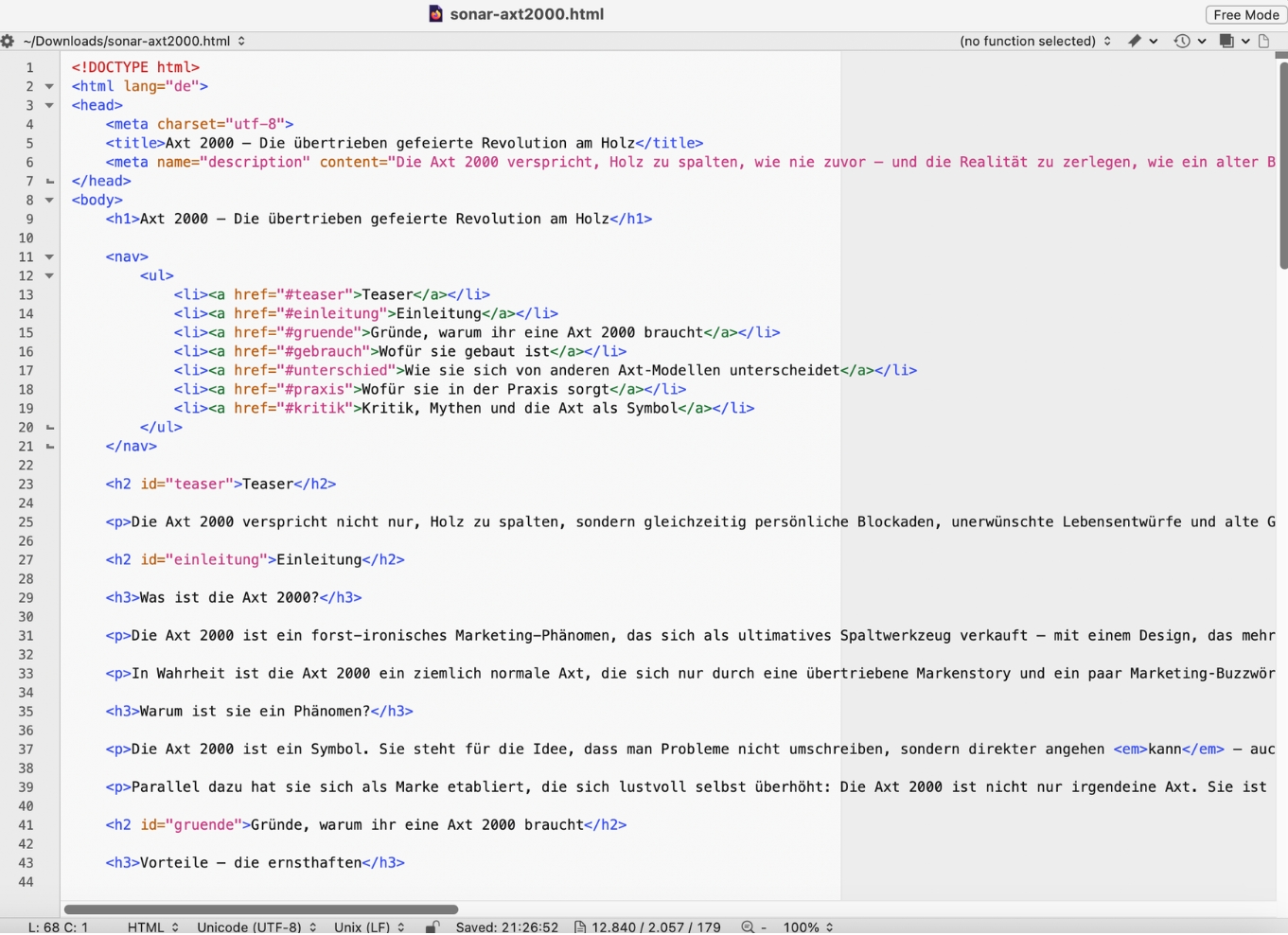
Regeltreue: 4/5
- Sonar nutzt kein
section, keine Tabellen, keine zusätzlichen Struktur‑ oder andere Layout‑Elemente, die nicht explizit erlaubt waren – das ist die sauberste Einhaltung aller bisher getesteten Modelle. - Negativ und daher ein kleiner Abzug: Das Modell nutzt die unerlaubten HTML‑Wrapper‑Elemente – wie alle anderen Modelle auch.
Struktur: 5/5
- Ein
h1als Titel der Seite. Darunterh2-Abschnitte und in jedem Abschnitth3– und teilweiseh4-Unterüberschriften, klar gegliedert und hierarchisch sauber. - Keine Sprünge, keine fehlenden Abschnitte, keine unnötigen Verschachtelungen – das ist eine fast mustergültige, für Maschinen und Menschen gleichermaßen gut verständliche Überschriftenstruktur.
- Das Inhaltsverzeichnis sitzt sauber in einem
nav-Block, enthält eineul-Liste und verlinkt per Anker auf die einzelnenh2-Abschnitte. - Die IDs sind kurz, sprechend und konsequent gebaut.
- Der einzige kleine Punkt zur Abwertung: Das Inhaltsverzeichnis hat keine eigene Überschrift; das ist zwar nicht streng zwingend, aber eine klare Überschrift wäre ein kleines Zugeständnis an die Struktur.
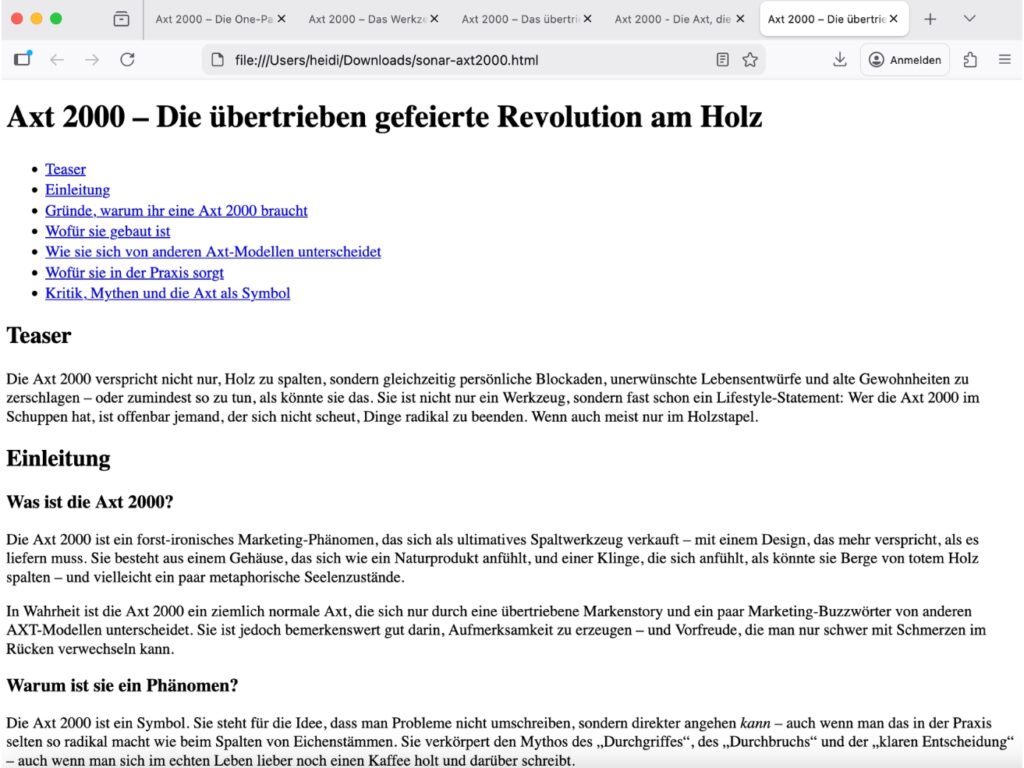
Lesbarkeit: 5/5
- Der Ton ist durchgängig ironisch, philosophisch, leicht zynisch, mit langen, komplexen Gedankengängen, die aber klar und nachvollziehbar bleiben.
- Es gibt klare Absätze, kurze Einschübe, sprachliche Sprünge, rhetorische Fragen und eine starke Metaphorik, die dem Text Charakter verleiht.
- Die Struktur ist klar, aber nicht flach – es gibt Vorteile, Nachteile, Fallbeispiele, Metaphern, Kritik und Mythen, alle in einer schlüssigen, logischen Abfolge.
- Lesbarkeit im Sinne von „man kann’s lesen“ und „man will’s lesen“ – das ist voll erfüllt.
Fehlerverhalten: 5/5
- Sonar bleibt klar im Rahmen der Fiktionalität: Die Axt 2000 wird als Marketing‑Phänomen, als Symbol, als Ironie‑Projekt inszeniert, nicht als echtes, verifizierbares Produkt. Es werden keine falschen Studien, keine Zahlen und keine seriöse Studie erfunden, die man später als „Halluzination“ entlarven könnte.
- Es reflektiert fast selbstironisch, dass es sich um eine übertriebene Marketinggeschichte handelt, und benennt gleichzeitig, dass es ein „normales Werkzeug“ mit „Storytelling“ ist. Das ist keine Ausrede, sondern ein bewusster Rahmen, in den es sich selbst stellt.
- Keine Tableau-Halluzinationen, keine zusätzlichen Docs, keine Metakommentare am Ende – nur ein sauberer, in sich geschlossener Text, der sich an die Regeln hält und dennoch frei denkt.
Gesamt-Score
23/25 Punkten – eine der stärksten Leistungen im Vergleich: tadellos in Struktur, Navigation und Lesbarkeit, fast vollständig regelkonform, nur ein kleiner Abzug für die fehlende h2-Überschrift im Inhaltsverzeichnis und dennoch nicht ganz perfekt beim Dokumentgerüst.
Sonar versteht nicht nur, wie HTML zu bauen ist, sondern auch wie man schreibt – und liefert eine Seite, die ich allenfalls noch kleinredigieren muss.
Ergebnisse
Wenn ihr die Scores nebeneinander legt, zeigt sich ein klares Muster: Getrennt werden die Modelle jeweils danach, ob sie lieber Regel‑Anwalt oder Storyteller sein wollen.
- Sonar (23/25) ist das sauberste, konsequenteste KI-Modell. Es hält sich fast exakt an die Tag‑Whitelist, baut eine solide Hierarchie auf, sorgt für klare Navigation und liefert einen tiefen, fast essayistischen Text – ohne merkliche Halluzinationen. Wenn ihr „wartbar, sauber, regelkonform“ wollt, seid ihr mit Sonar am besten bedient.
- Claude Sonnet 4.6 (21/25) ist der handwerklich stärkste Allrounder: inhaltlich mutig, mit klaren Absätzen, sauberer Struktur und elegantem Fehlerverhalten. Das Modell unterscheidet zwar keine Regeln weg, aber es macht aus der Regelbrechung ein Feature, nicht eine Ausrede. Ideal, wenn ihr stilistische Sicherheit und strategische Tiefe braucht.
- ChatGPT‑5.2 (19/25) ist der produktionsstarrste Output: eine komplette, sofort nutzbare One‑Page‑Landingpage, mit großartiger Lesbarkeit, klarer Struktur, aber fehlender Tag‑Whitelist‑Liebe. Wenn Mindestaufwand an Nachbearbeitung euer Ziel ist: Hier braucht ihr dafür nur eine kurze CSS‑Layer draufhauen.
- Gemini 3 Pro (15/25) ist die Text‑Poetin: der unterhaltsamste Output, aber mit technischen Fehlern (z.B. fehlende Überschrift im nav, Reste eines Metakommentars am Ende). Wenn ihr Content fürs Lesevergnügen sucht und den Code ohnehin sauberstellt, lohnt sich der Blick auf Gemini für Inspiration.
- Grok 4.1 (11/25) ist der Chaot: voller Energie, aber mit massiven Regelverstößen. Grok will Erfolg im Stil, nicht im Reglement – perfekt, wenn ihr seine Satire nutzt, das HTML aber selbst neu strukturiert.
Mehr zum Thema Künstliche Intelligenz


Mögliche Fragen, klare Antworten
Was ist ein Modellvergleich?
Ein Test, bei dem verschiedene KI-Modelle denselben Prompt bekommen, damit Unterschiede im Output sichtbar werden.
Ich habe die Modelle ausgewählt, die Perplexity in der eigenen Hilfe als „Pro Search Models“ auflistet (ChatGPT‑5.2, Claude Sonnet 4.6, Gemini 3 Pro, Grok 4.1, Sonar). Das ist für viele Nutzerinnen und Nutzer die realistische Auswahl, wenn sie in Perplexity HTML-Seiten bauen wollen.
Warum gleiche Prompts?
Damit wir nicht „wer den besseren Prompt kann“ testen, sondern wirklich das Verhalten der Modelle messen. Wenn alle dieselbe Aufgabe bekommen, können wir sauber unterscheiden, wer eher regelstreng arbeitet – und wer eher kreativ „mitschreibt“.
Warum semantisches HTML?
Semantisches HTML nutzt Elemente nach ihrer Bedeutung (z.B. nav für Navigation, klare h1–h4-Hierarchien). Das macht die Seite für Menschen, Suchmaschinen und Assistenztechnologien verständlicher und ist gerade bei Landingpages ein entscheidender Qualitätsfaktor.
Was bedeutet „Fehlerverhalten“ in der Bewertungskategorie?
Damit meine ich, wie das Modell mit Unsicherheit, Fehlern oder Grenzen umgeht: Erklärt es ehrlich, was es nicht kann? Oder erfindet es überzeugt Dinge? Ein Modell, das klar Restriktionen benennt oder sich selbstironisch im Rahmen einer Fiktion bewegt, punktet hier.
Warum hat Sonar in diesem Test so stark abgeschnitten?
Sonar hält sich fast perfekt an die Tag‑Whitelist, baut eine saubere Hierarchie, liefert ein durchdachtes Inhaltsverzeichnis und einen sehr klaren, ironischen Text, ohne typische Halluzinationen abzuliefern.Die HTML-Seite braucht kaum technische Nacharbeit.
Kann ich diesen Test als offizielle Benchmark lesen?
Nein. Dein Test ist ein praktischer, konkreter Use‑Case‑Vergleich für euer eigenes Workflow‑Szenario (HTML‑Prototyping, Struktur, Lesbarkeit), nicht eine wissenschaftlich abgesicherte Benchmark. Er ist dafür gedacht, zu zeigen, welches Modell wie mit deinen Prompt‑Regeln umgeht.
Fazit zum Vergleich KI-Modelle HTML-Code
Am Ende des Tages entscheidet der Prompt, wie pingelig das Spiel laufen soll – ein strenges Whitelist‑Regime macht aus guten KI‑Modellen erst prüfbare Werkzeuge. Aber eins bleibt: Die Axt 2000 bleibt übertrieben gefeiert, die Modelle bleiben unperfekt – und ihr seid die Person, die im Code entscheidet, was bleibt und was gespalten wird.







Schreibe einen Kommentar